先按照顺序列一下这几篇技术首次提交到arxiv的时间,我们按照提交时间来介绍,很多博客都搞不清楚发表时间,甚至把这几种方法张冠李戴,我们还是从原始信息源头进行梳理,这样虽然慢但是可靠。
论文:Adapter: Parameter-Efficient Transfer Learning for NLP 代码:Adapter 时间:2019.2.2
论文:Prefix-Tuning: Optimizing Continuous Prompts for Generation 代码:Prefix-Tuning 时间:2021.01.01
论文:P-tuning: GPT Understands, Too 代码:P-Tuning 时间:2021.03.18
论文:The Power of Scale for Parameter-Efficient Prompt Tuning 代码:Prompt Tuning 时间:2021.4.18
论文:LoRA: Low-Rank Adaptation of Large Language Models 代码:Lora 时间:2021.06.17
论文:BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models 代码:BitFit 时间:2021.06.18
论文:P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks 代码:P-Tuning v2 时间:2021.10.14
论文:T-Few: Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning 代码:T-Few 时间:2022.04.11
P-Tuning v2
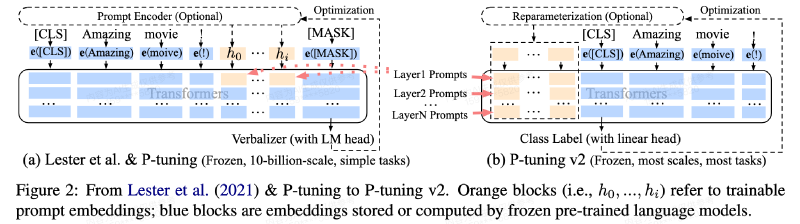
P-Tuning和P-Tuning v2的一作是相同的,这篇文章也是一张图说明白。下图左边的Lester et al.代表的是Prompt Tuning这篇论文,也就是说Prompt Tuning和P-Tuning的做法基本一样(它们的区别可以在我介绍Prompt Tuning的这篇博客里找到),它们都是通过在输入层加入可学习prompt来进行模型微调的,但右边P-Tuning v2则是在每一层而不只是输入层加了可学习的prompt。
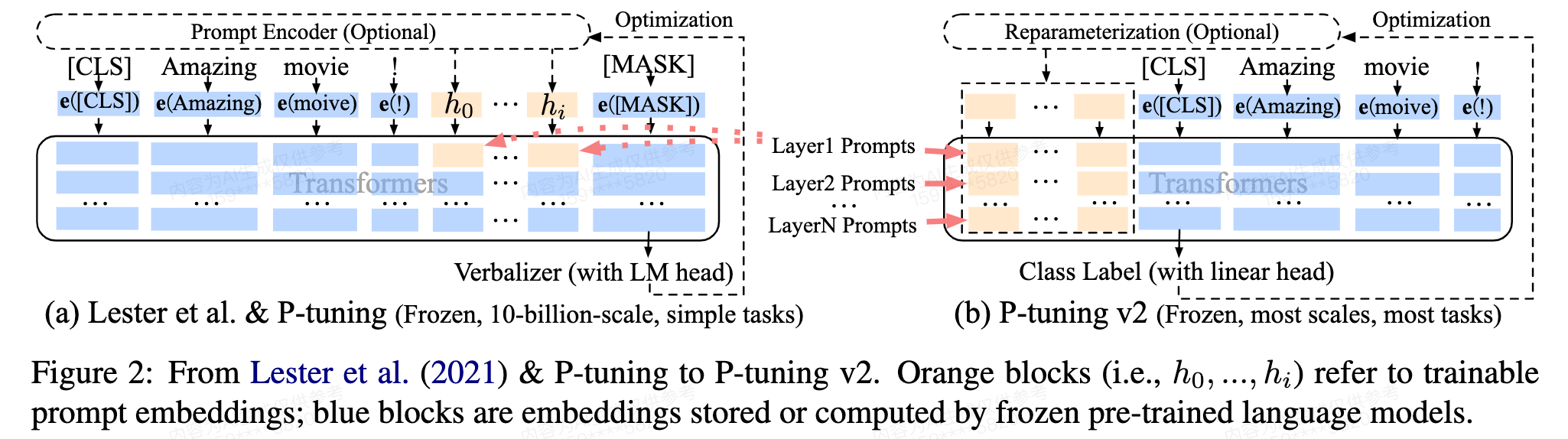
仔细看看还有底下的区别,也就是Verbalizer和ClassLable,这是自然语言理解(NLU)任务中的不同输出方法。它们的区别是,Verbalizers通常用于少量样本的学习场景,而Class Label则适用于有大量标注数据的微调。
Verbalizers(with LM head): LM head(语言模型头部)是指在预训练语言模型的顶部用于生成文本的输出层,模型输出被映射到一个或多个自然语言词汇(即verbalizers)。 就比如下图情感分析的例子,简单来说也就是把理解任务当成生成任务做,输入一段话,模型可能输出bad等代表消极的词,或者good,wonderful与great等代表积极的词,通过verbalizer做一个简单映射,生成最后的标签"positive"或"negative"。

Class Label(with Linear head): Class label方法是在微调预训练模型时更传统的方法。在这种方法中,每个输出类别直接对应于一个类别标签。Linear head(线性头部)是一个简单的全连接层,它将模型的最后一个隐藏层的输出映射到类别标签的概率分布。一般通过softmax函数为每个类别生成一个概率。 简单来说也就是把理解任务当成分类任务,比如分类成第0类还是第1类。注意看图,linear head加在分类头(CLS)上。
区别
P-Tuning v2在每一层都用prompt,这不是和Prefix-Tuning一样了吗?确实,严格来说P-Tuning v2和Prefix-Tuning就是一样的,不同的是Prefix-Tuning是在NLG(自然语言生成)上做实验的,所以用的是左边的Verbalizers(with LM head)模式。另外一个差别是,Prefix-Tuning的生成软prompt的做法叫做reparameterization,也就是先初始化一个nn.parameter,然后用mlp或者lstm变换一下,再作为输入网络的软prompt。而P-Tuning v2则是把这个mlp或lstm拿掉了,直接用nn.parameter作为软prompt。
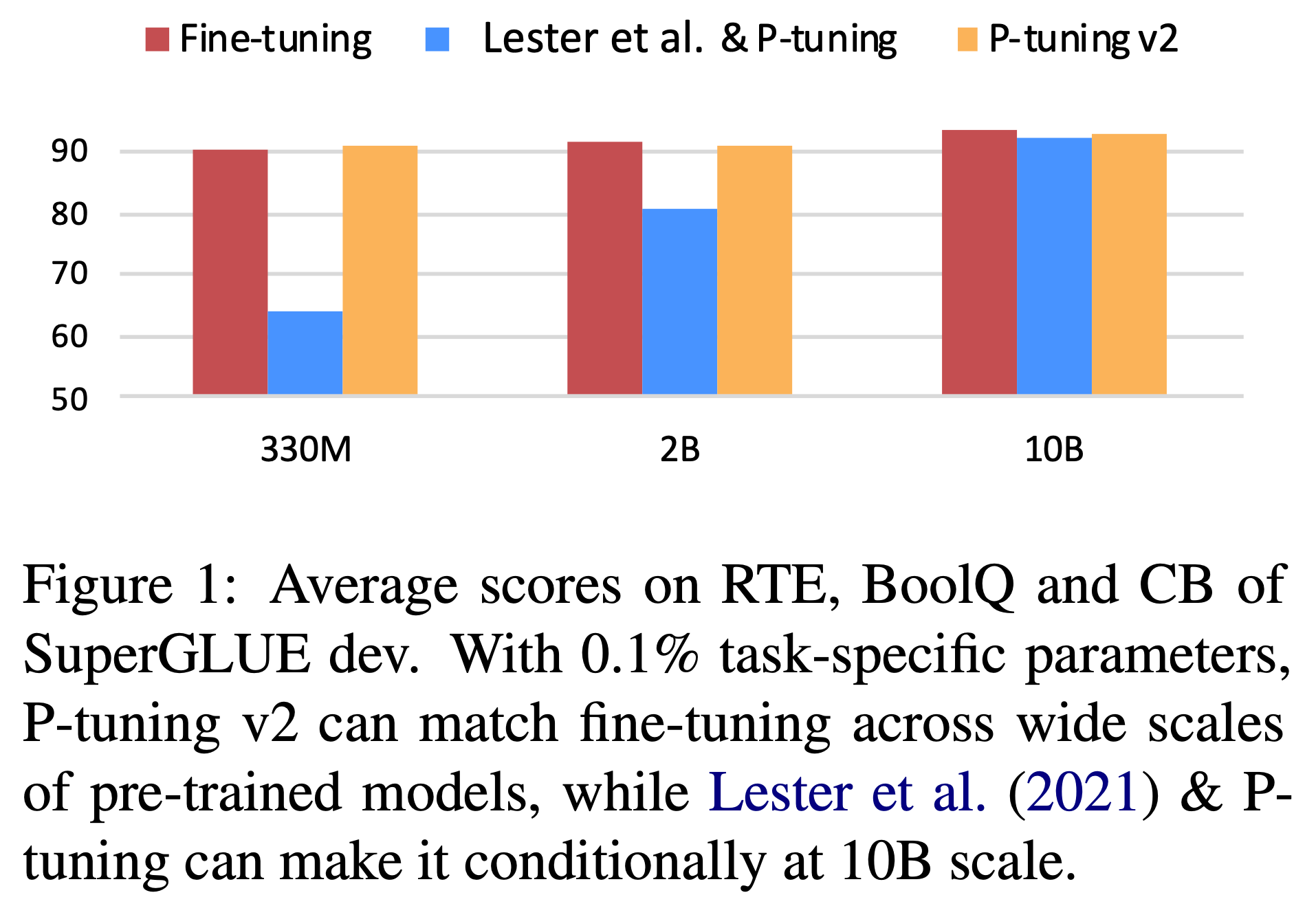
在提出新方法之前要说明旧方法有什么问题,Prompt Tuning和P-Tuning的问题是缺乏跨规模的普适性,当模型扩展到超过10亿个参数时,Prompt Tuning可以与微调相媲美。然而,对于广泛使用的中小型模型(从100M到1B),Prompt Tuning的性能比微调差得多,如下图所示。再提一遍,下图的Lester et al.代表的是Prompt Tuning这篇论文。
另外Prompt Tuning没有在复杂的NLU任务上验证有效性,比如序列标注任务。作者发现在序列标注任务上,Prompt Tuning也是比不过微调的。
啥是序列标注任务呢?一个典型的序列标注任务的例子是命名实体识别(Named Entity Recognition, NER)。NER的任务是从文本中识别和分类出具有特定意义的实体,例如人名、地名、组织名等。以下是一个NER任务的示例: 文本: “李雷和韩梅梅一起去纽约玩。” 标注: 李雷 (PER) 和 (O) 韩梅梅 (PER) 一起去 (O) 纽约 (LOC) 玩 (O) 在这个例子中,文本中的人名“李雷”和“韩梅梅”被标注为PER(人名),而“纽约”被标注为LOC(地点)。其他词如“和”和“玩”等不涉及实体,因此标注为O(其他)。NER任务的目标是通过学习这些标注信息,让模型能够预测新的文本中每个单词的实体类型。
方法
改变1: P-Tuning v2提出的第一个改变就是在每一层加入可学习的软prompt,这样一来可学习参数就更多了(from 0.01% to 0.1%-3%),这允许了更多的任务容量,另外实验发现添加到更深层的软prompt对模型预测有更直接的影响。
改变2:
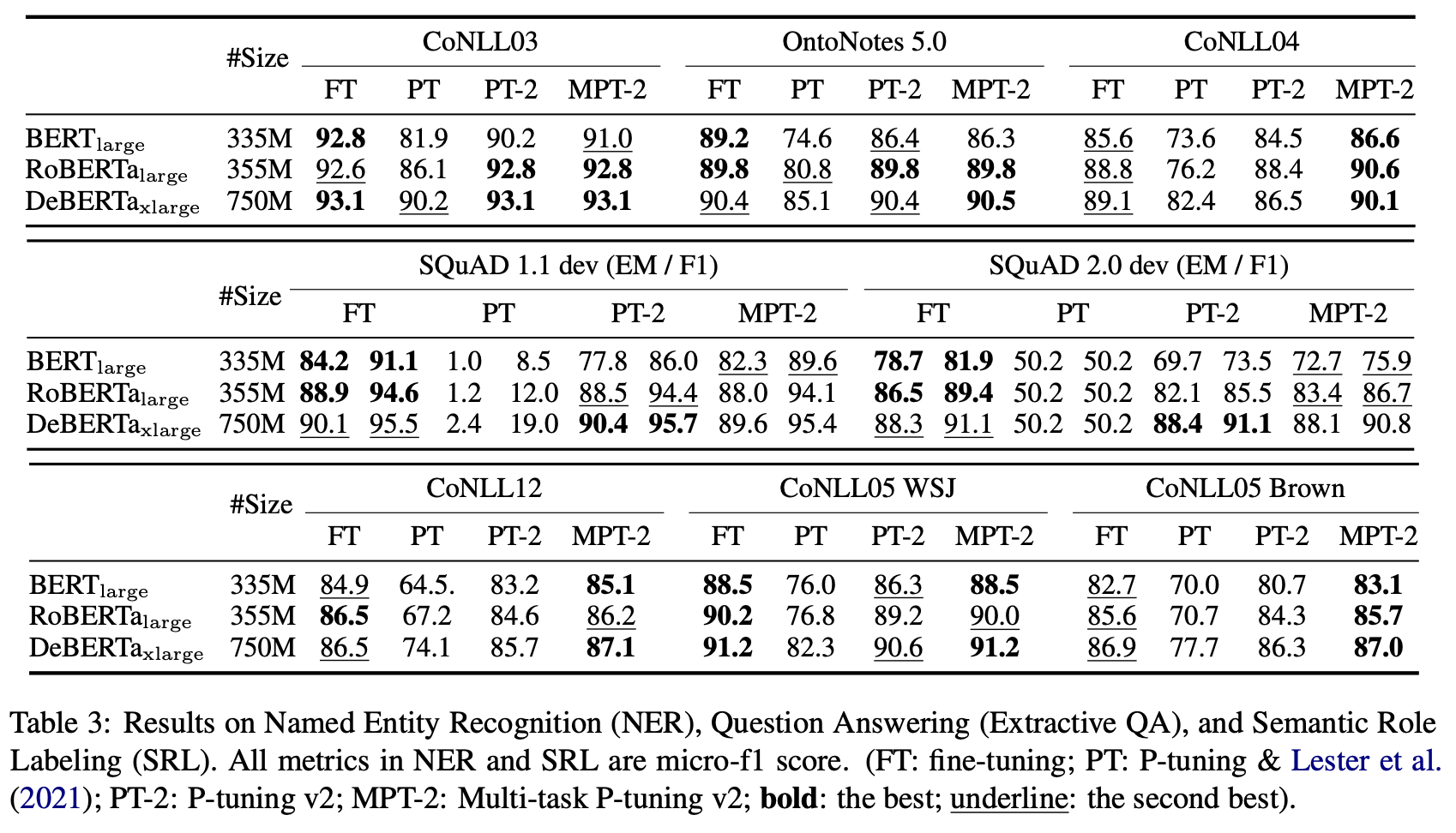
另外的改变就是拿掉了reparameterization,实验发现对于NLU来说,reparameterization的有用性取决于任务和数据集。对于一些数据集(例如,RTE和CoNLL04),MLP层带来了持续的性能改进;而对于其他数据集,MLP层对结果的影响最小,甚至可能是负面的(例如,BoolQ和CoNLL12),如下图所示:
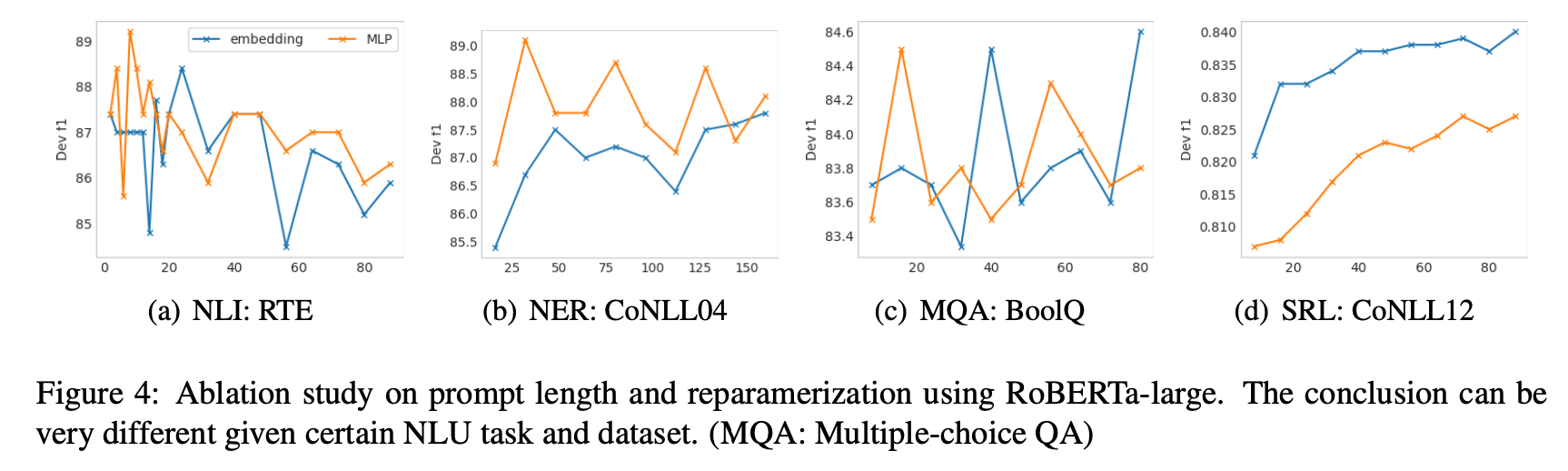
从上图还能看出来,对于简单的NLU任务,通常较短的提示就足够获得最佳性能;对于复杂的序列任务,通常超过100的较长提示会有所帮助。reparameterization与最佳提示长度也有着密切的联系。例如,在RTE、CoNLL04和BoolQ中,reparameterization比embbeding更早地达到最佳结果。
改变3: 使用LM head结合verbalizers一直是prompt tuning的主要做法,但是本文发现数据量大时不需要这样做,同时这种方法与序列标注不兼容(比如类别PER,O等标识在verbalizers中是不太能建立关联的),所以P-tuning v2改为在BERT的token上应用随机初始化的分类头,把每个token映射到一个类别上。
实验
注意,本文所有的实验都是在全量数据下进行的实验,在SuperGLUE(一个NLU的评测数据集)上,P-Tuning v2仅仅学习0.1%的参数,在不同的模型大小上都能接近全参数微调,但是P-Tuning和Prompt Tuing在小尺寸的模型(330M)上是比较差的,而在大尺寸模型(2B到10B)上,它们才能够与P-Tuning v2追平。
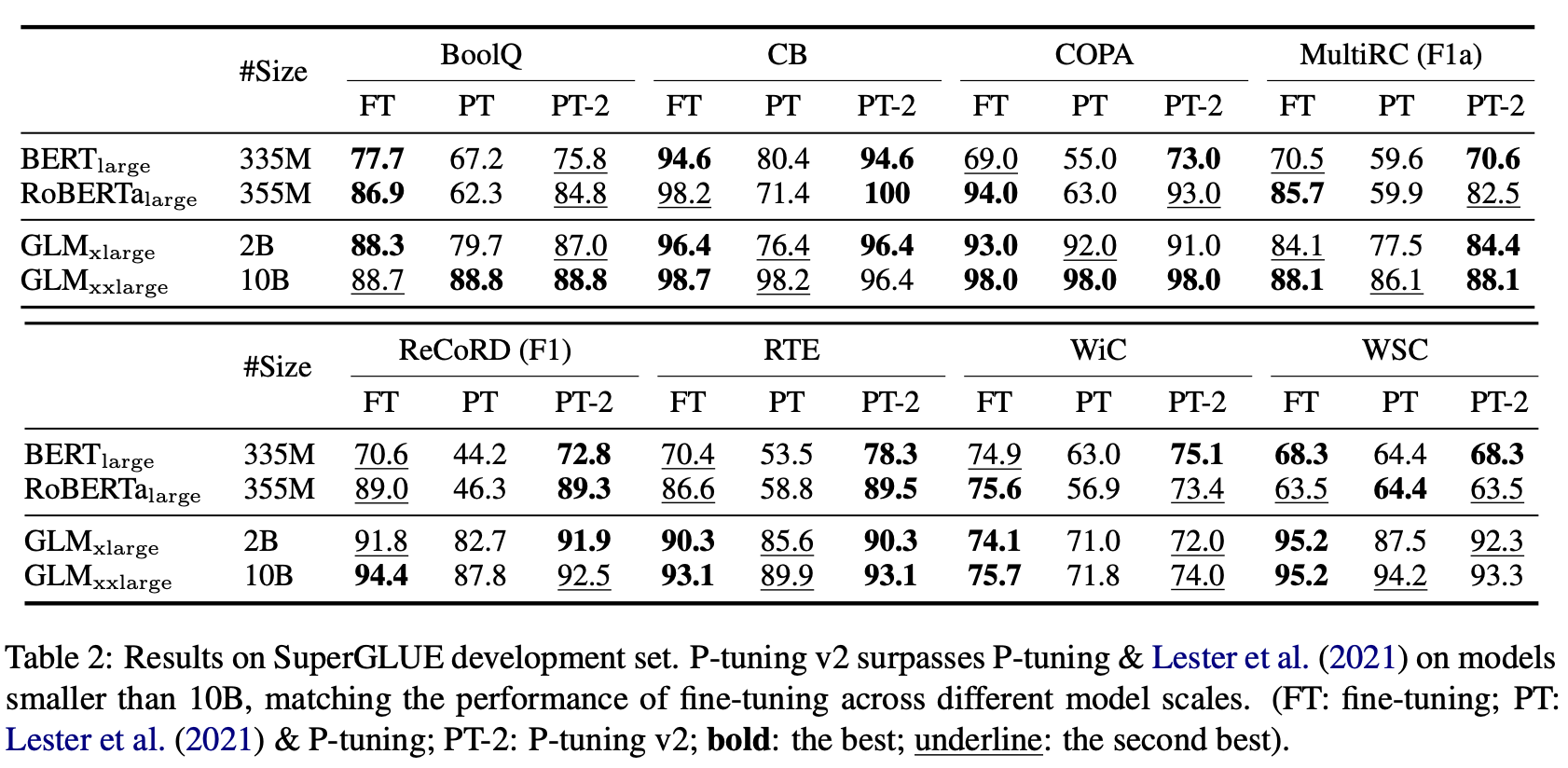
在NER等挑战性的任务上,P-Tuning和Prompt Tuing出现了异常结果,比如SQuAD 1.1上,但是P-Tuning v2和全参数微调能够打得有来有回。表中的多任务学习设定中,对于不同任务使用不同分类头,但是共享软prompt。
在之前的研究中,Verbalizers(with LM head)是大家都用的主导方法,作者保持其他方面不变,只是把它替换成Class Label(with Linear head),结果表明两个之间没有明显效果差异,这说明在数据足够的时候,微调一个几千个参数的Linear head是没什么问题的。

另外,作者还讨论了往深层加软prompt和往浅层加软prompt,哪个效果更好。比方说网络有20层,现在决定在其中的十层中添加,有降序和升序两种方式,发现降序的方式总比升序好,也就是说往更深层添加prompt效果更好,虽然它们的可学习的参数是一样的。在RTE中,只在第17-24层添加提示就可以获得非常接近所有层的性能。

这篇文章总体来说新颖性有限,因为它的核心想法和Prefix Tuing相同。但是这篇文章让我更了解了NLP的一些子任务,比如NER,QA和SRL。现在简单介绍一下这些子任务以及说一下这篇文章在这些子任务上的做法。
NER(命名实体识别) NER任务在前面已经介绍过了,这里使用IOB2格式进行标注,啥是IOB2标注呢?如下:
假设我们有一个句子:“John Doe and Jane Smith are software engineers at Google in California.” 在这个句子中,我们有两个人名:“John Doe”和“Jane Smith”,一个组织名:“Google”,以及一个地点名:“California”。使用IOB2格式进行标注,我们会得到以下结果: John: B-PER (开始一个人名实体) Doe: I-PER (人名实体内部) and: O (不属于任何实体) Jane: B-PER (开始另一个人名实体) Smith: I-PER (人名实体内部) are: O (不属于任何实体) software: O (不属于任何实体) engineers: O (不属于任何实体) at: O (不属于任何实体) Google: B-ORG (开始一个组织名实体) in: O (不属于任何实体) California: B-LOC (开始一个地点名实体) 在这个例子中,“B-”标签用于标记实体的开始,而“I-”标签用于标记实体的后续部分。这种方式可以帮助模型区分连续的实体,如“John Doe”和“Jane Smith”,即使它们由相同类型的词组成,也能被正确地识别为两个独立的实体。同样,“Google”作为一个单词的组织名,只需要一个“B-ORG”标签,而“California”作为地点名也只需要一个“B-LOC”标签。通过这种方式,可以清晰地识别和区分句子中的不同实体及其类型。
这篇文章的做法就是对每个token生成一个分类预测,预测它们是上面分类中的哪一种。通过这样来解决序列标注任务。
QA(抽取式回答) QA旨在从给定的上下文中提取出问题的答案。在这个任务的数据集中,每个答案都是上下文中的一个连续片段。按照传统将这个问题形式化为序列标注问题,通过为每个词分配两个标签之一:“开始”或“结束”,最后选择最有信心的开始-结束对的片段作为提取的答案。如果最有信心的对的概率低于某个阈值,模型将认为这个问题是无法回答的。通过一个具体的例子来说明抽取式问答(QA)的过程。
假设我们有以下上下文(context)和问题(question): 上下文(Context): “The Eiffel Tower is located on the Champ de Mars in Paris, France.” 问题(Question): “Where is the Eiffel Tower located?” 在这个例子中,答案显然是 “on the Champ de Mars in Paris, France”。现在,我们的任务是使用一个模型来识别这个答案。模型会为上下文中的每个词分配一个“开始”和“结束”标签的概率。这些概率表示模型对于每个词是答案开始或结束的信心程度。 假设模型给出了以下概率: The: 开始(0.01), 结束(0.01) Eiffel: 开始(0.02), 结束(0.01) Tower: 开始(0.01), 结束(0.01) is: 开始(0.01), 结束(0.01) located: 开始(0.01), 结束(0.01) on: 开始(0.90), 结束(0.01) the: 开始(0.01), 结束(0.01) Champ: 开始(0.01), 结束(0.01) de: 开始(0.01), 结束(0.01) Mars: 开始(0.01), 结束(0.01) in: 开始(0.01), 结束(0.01) Paris: 开始(0.01), 结束(0.80) France: 开始(0.01), 结束(0.90) 在这里,我们可以看到模型给出了最高的“开始”标签概率给了单词 “on”(0.90),而最高的“结束”标签概率给了单词 “France”(0.90)。这意味着模型非常有信心答案的开始是 “on”,结束是 “France”。 因此,我们会选择 “on the Champ de Mars in Paris, France” 作为答案,因为这是从最有信心的开始标签到最有信心的结束标签之间的连续文本片段。 如果我们设定了一个阈值,比如说0.5,那么只有当模型对开始和结束标签的信心都超过这个阈值时,我们才会认为找到了一个有效的答案。在这个例子中,由于 “on” 和 “France” 的概率都远远超过了0.5,我们可以自信地输出这个答案。如果所有的开始和结束概率都低于阈值,那么模型将判断这个问题是无法回答的。
所以,QA任务在这里其实也转换成了一个分类问题。
SRL(语义角色标注) SRL将标签分配给句子中的单词或短语,以指示它们在句子中的语义角色。我们通过一个具体的例子来说明SRL。
假设我们有以下句子: 句子:“Alice gave Bob a book at the library.” 以下是语义角色标注结果: Alice: ARG0 (施事者,即行动的执行者) gave: V (动词) Bob: ARG1 (受事者,即行动的接受者) a book: ARG2 (主题,即被传递的物体) at the library: ARGM-LOC (地点修饰语,说明行动发生的地点) 在这个例子中,“Alice” 是行动的执行者,因此被标注为 ARG0;“gave” 是句子中的动词,被标注为 V;“Bob” 是行动的接受者,被标注为 ARG1;“a book” 是被传递的物体,被标注为 ARG2;“at the library” 描述了行动发生的地点,被标注为 ARGM-LOC。
SRL模型会对句子中的每个词进行这样的分析,然后分配相应的标签。模型会考虑到句子中的上下文信息,分析每个词与目标动词(上例中的 “gave”)之间的关系。但是一个句子可能包含多个动词,这时候咋办呢?本文就是将想要的目标动词添加到句子后面,明确指示模型应该关注哪个动词的语义角色。还是举例吧:
原始句子:“Alice gave Bob a book and then went to the library.” 在这个句子中,有两个动词:“gave”和“went”。假设我们想要标注与动词“gave”相关的语义角色。我们可以修改句子,将“gave”作为目标动词添加到句子末尾: 修改后的句子:“Alice gave Bob a book and then went to the library. gave” 现在,模型知道需要关注与“gave”这个动词相关的语义角色。接下来,模型会使用线性分类器对每个单词进行分类,基于它们与目标动词“gave”的关系。标注结果可能如下: Alice: ARG0 (施事者,给出书的人) gave: V (目标动词) Bob: ARG1 (受事者,收到书的人) a book: ARG2 (主题,被给出的物体) and: O (不属于与目标动词“gave”相关的语义角色) then: O (不属于与目标动词“gave”相关的语义角色) went: O (不属于与目标动词“gave”相关的语义角色) to: O (不属于与目标动词“gave”相关的语义角色) the library: O (不属于与目标动词“gave”相关的语义角色)
通过这种方式,模型可以专注于与特定动词相关的语义角色,并准确地为句子中的每个词分配标签。如果想要分析与另一个动词“went”相关的语义角色,可以类似地修改句子,将“went”作为目标动词添加到句子末尾,并进行相应的标注。所以SRL任务也就是一个多分类任务。
好嘞,这篇文章就到此结束啦!下篇再见。