先按照顺序列一下这几篇技术首次提交到arxiv的时间,我们按照提交时间来介绍,很多博客都搞不清楚发表时间,甚至把这几种方法张冠李戴,我们还是从原始信息源头进行梳理,这样虽然慢但是可靠。
论文:Adapter: Parameter-Efficient Transfer Learning for NLP 代码:Adapter 时间:2019.2.2
论文:Prefix-Tuning: Optimizing Continuous Prompts for Generation 代码:Prefix-Tuning 时间:2021.01.01
论文:P-tuning: GPT Understands, Too 代码:P-Tuning 时间:2021.03.18
论文:The Power of Scale for Parameter-Efficient Prompt Tuning 代码:Prompt Tuning 时间:2021.4.18
论文:LoRA: Low-Rank Adaptation of Large Language Models 代码:Lora 时间:2021.06.17
论文:BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models 代码:BitFit 时间:2021.06.18
论文:P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks 代码:P-Tuning v2 时间:2021.10.14
论文:T-Few: Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning 代码:T-Few 时间:2022.04.11
LoRA
LoRA应该是使用最为广泛的LLM微调方法,国内外众多公司所谓的垂直领域模型都是使用LoRA微调出来的。
LoRA相比其他方法我觉得还是有一点牛逼的,因为它不会增加推理耗时,可以说对于最终模型的使用者可以说是一个无痛涨点的方法了,另外这篇论文也写得很好。
对比
在提出新方法之前,先要问一句现有的方法不好吗?作者分析了Adapter方法和prefix-tuning方法的问题。
对于Adapter方法来说,是没有办法来绕过新加的Adapter层的,虽然可以通过改变瓶颈层维度来让Adapter层运算量很小,但是实验发现即使新加的参数只有1%,仍然会显著增加延迟。这也好理解,因为在推理的时候,可能batch会比较小,模型算到Adapter层,无法榨干GPU,GPU很大一部分在空闲,无法利用起来,这时候速度就依赖于在算的几个核心,他们什么时候算完,Adapter层就结束计算,所以推理延迟没法改善,如下图所示。

这是测试时候的情况,但是训练应该不存在训练耗时增加很多的问题,因为训练耗时是吞吐和延迟的综合考量,训练的时候会用一些并行化技术,模型跑到Adapter层吃不满的时候可以做一些别的层的运算,所以GPU没闲着,因此训练耗时应该不会显著增加。这里作者也画了一些图,结论就是当batchsize越大,序列长度越长时,应用Adapter所带来的延迟百分比就越低,这也是预期内的,因为这时候并行越多(数据并行以及模型并行),GPU性能压榨的越干净,自然没啥闲着的资源,所以带来的延迟百分比越低,注意这里说的是百分比,不是说跑batchsize 2比batchsize 1速度还要快。

相较于prefix-tuning来说,前缀是比较难优化的,他们论文中也提到了这点,而且准确度也很难随着前缀的长度而增长。因为前缀越来越长的时候,留给任务的prompt就会越短,所以这种方法一定是有准确度上限的。
方法
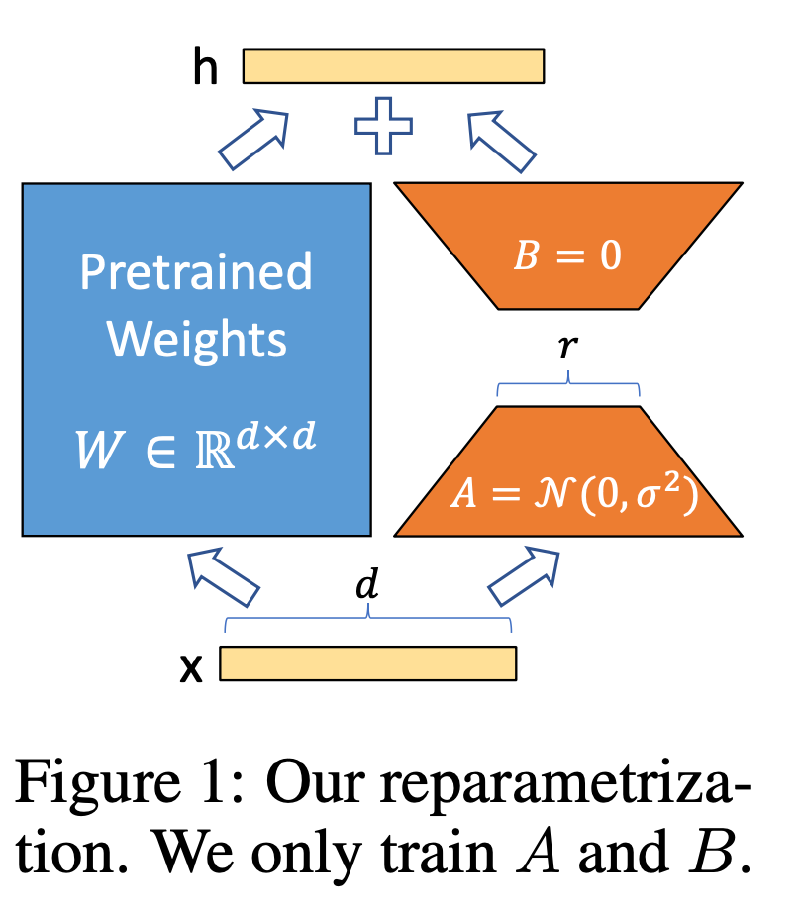
LoRA的方法也是挺简单的,一张图能够说明白。前人研究表明LLM具有低“内在维度”,也就是随机投影到一个更小的子空间,它们仍然可以有效地学习。
作者假设预训练的权重参数为$W_{0} \in \mathbb{R}^{d\times k}$,现在通过$\Delta W$来更新参数,新的权重参数是$W_{0}+\Delta W$,这里$B \in \mathbb{R}^{d\times r}$,$A \in \mathbb{R}^{r\times k}$,只要$r«min(d,k)$,那么新增加的学习参数就很小,$r$就叫内在秩。前向表示为$h=W_0x+\Delta Wx=W_0x+BAx$。 这里的$A$是用随机高斯初始化,$B$使用全0初始化。所以$\Delta W$在训练一开始的时候就是0。还记得我们前面提到Adapter也是通过类似的设计让新加的Adatapter层在一开始等于全等变化,这样初始化便于训练。
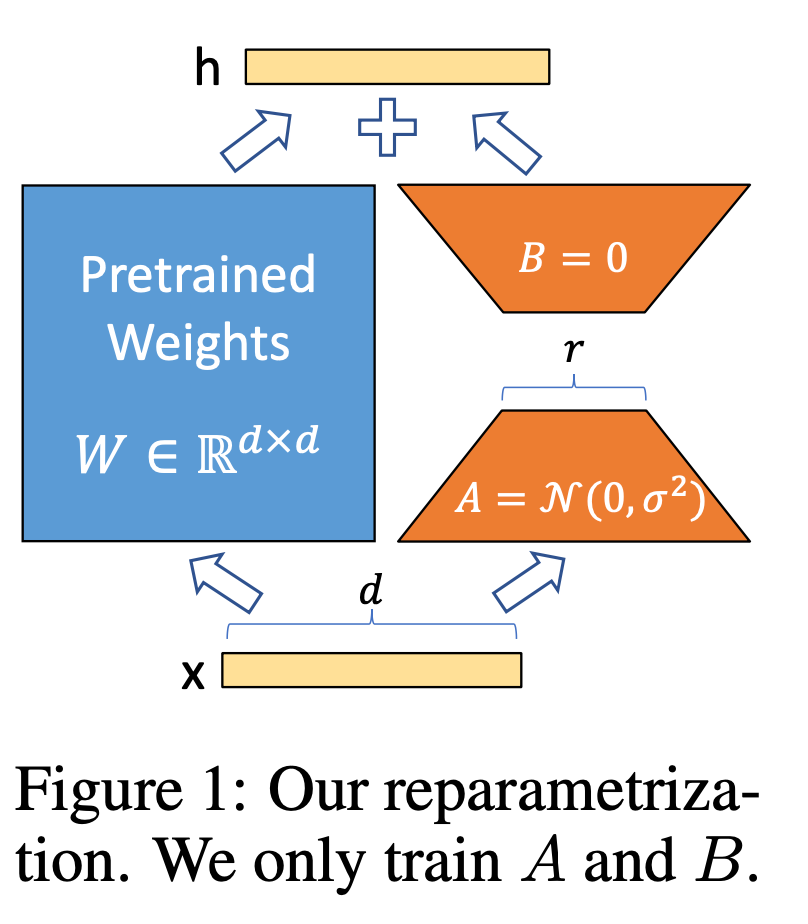
LoRA的好处就是没有推理延迟,因为一旦学习完了,让$W=W_0+BA$就行了,所谓的主路支路可以融合为一条路。
那LoRA主要是用在LLM中的哪些层呢?鉴于LLM都是基于Transformer的,而Transformer中有$W_q,W_k,W_v,W_o$四个权重矩阵,也就是query,key,value,output,称之为注意力矩阵,然后还有前馈层中的两个全连接层,这些理论上都是可以用到LoRA的地方。在这篇论文的实验中,作者只对注意力矩阵用LoRA,而且只对$W_k,W_v$用了,全连接层没用。
实验
从实验上看,对于一个用Adam训练的大型Transformer,如果r ≪ dmodel,显存使用量减少多达2/3,因为不再需要为冻结的参数存储优化器状态。具体来说,在GPT-3 175B上,训练过程中的显存消耗从1.2TB降至350GB。当r = 4时,模型大小减少了大约10,000倍(从350GB到35MB)。同时,因为不需要为绝大多数参数计算梯度,与完整的微调相比,在GPT-3 175B上训练时速度提高了25%。
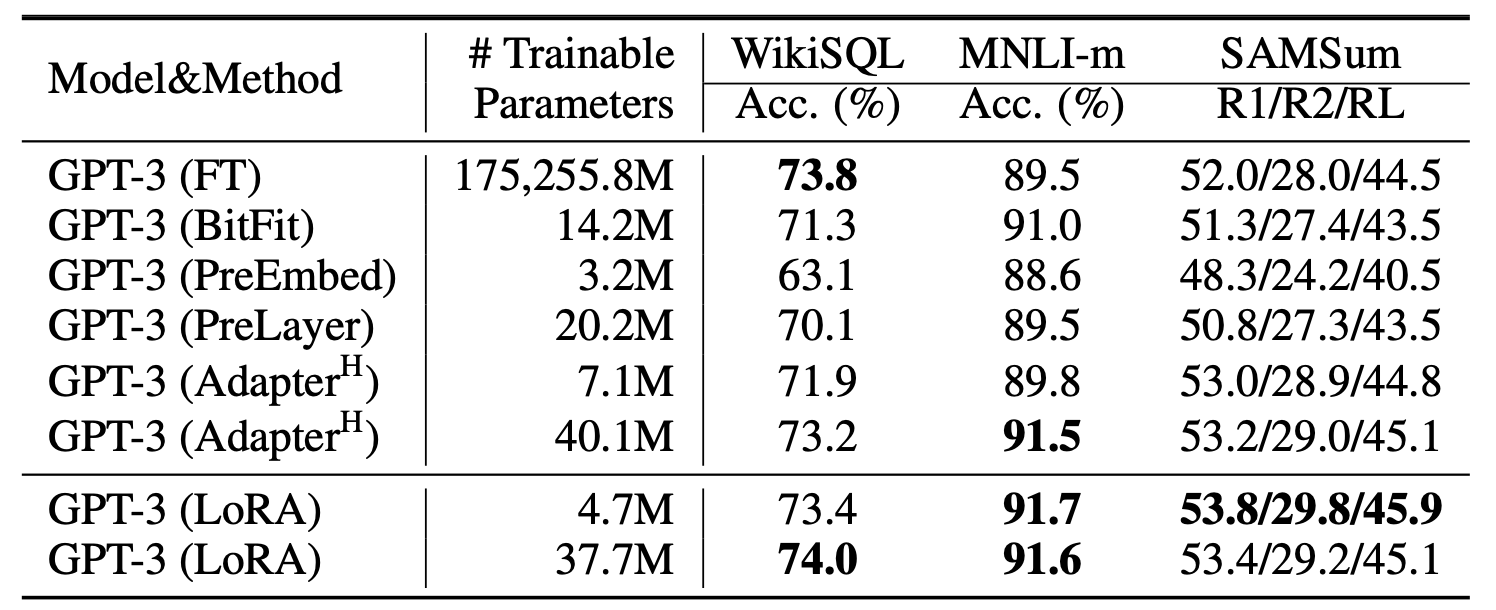
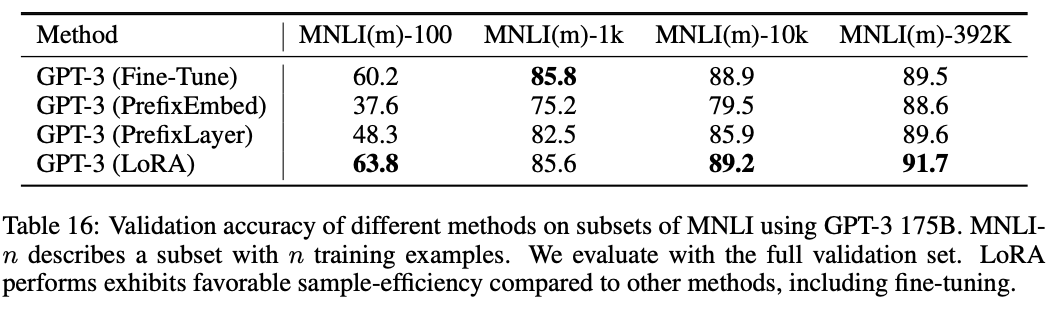
作者使用GPT3在不同数据集上进行了实验,这里的PreEmbed相当于prefix-tuning只对输入层做,而PreLayer则是对每一层transformer都做,我理解PreLayer其实也就是prefix-tuning的完整形态。 从实验结果上看,lora是挺棒的,取得了最好的效果,而且还超过了全参数微调(这里应该是数据量的问题,数据量不够,把大模型的能力搞坏了)。
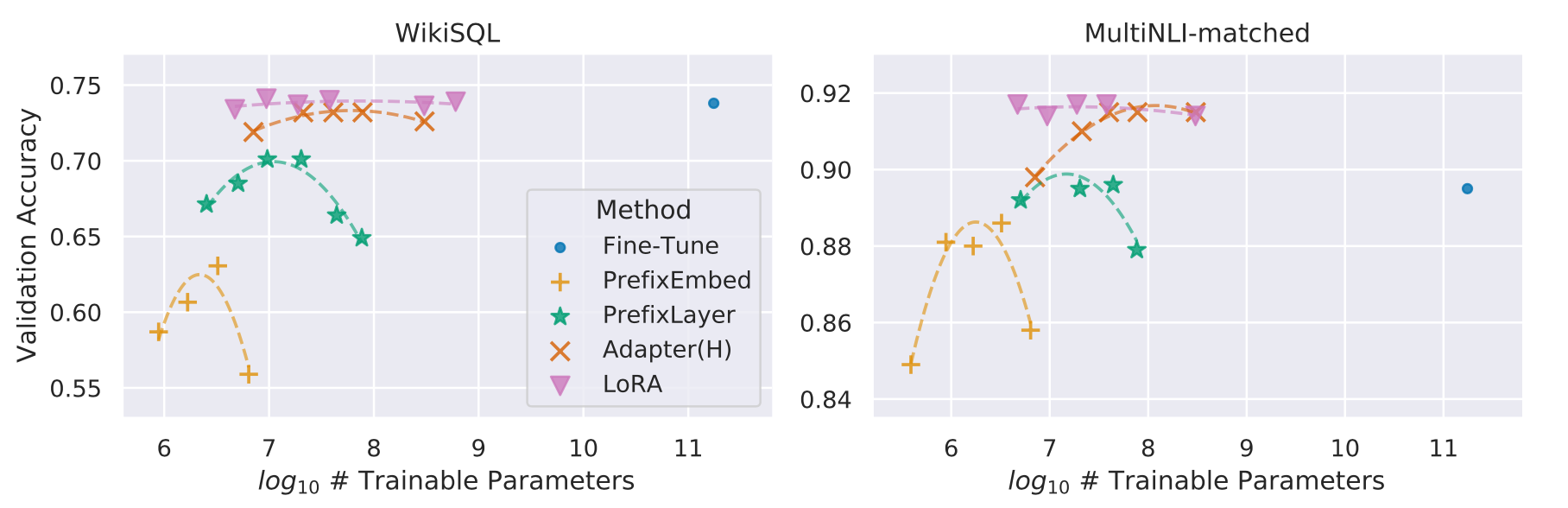
还有一个有意思的现象,就是对于这些微调方法而言,并不是可学习的参数越多,模型效果就越好,其他方法在堆学习参数的时候,准确率出现了先升高后下降的现象,LoRA也有,但是稍微好一点。作者猜测对于prefix-tuning来说,原因可能是这种输入数据偏离了预训练数据的数据分布。
这篇论文还讨论了对于超大模型在少量数据上,不同微调方法的精度,发现prefix-tuning在数据量小时,效果非常差,随着数据量上来了,才慢慢追平LoRA。
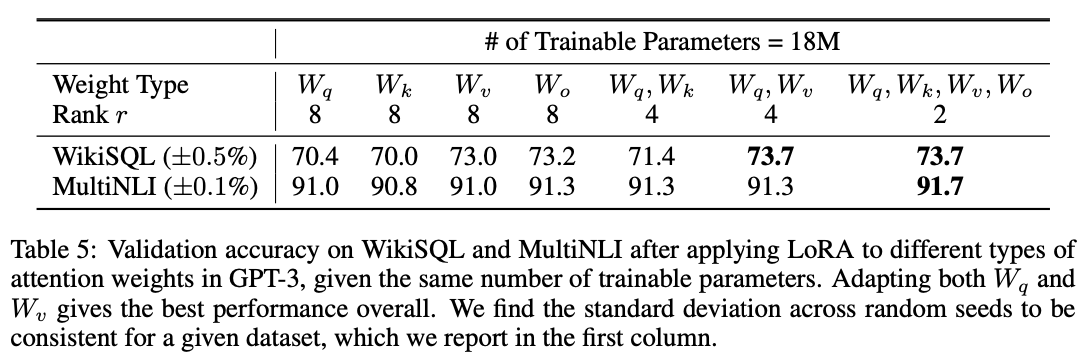
作者对LoRA如何应用也做了实验,假定现在可学习的参数量是一样的,一种方法是只对某一个注意力矩阵,如$W_q$应用LoRA,可以使其$r=8$,另一种方法是对四个注意力矩阵都应用LoRA,自然r要减少到$r=2$。从结果来看显然后者效果更好,只对$W_k,W_v$两个矩阵用也不错。但是只对某一个矩阵用效果比较差。
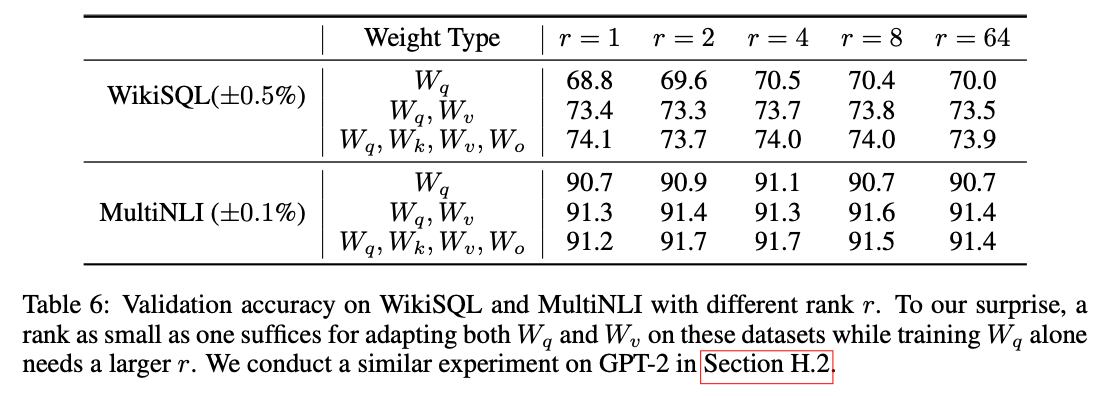
另一个有意思的实验是发现大模型的内在秩应该是很小的,$r=4$就能收获不错的精度,再增加也没啥进步了。
LoRA论文就介绍到这里了,其实原文还进行了大量的实验,比如LoRA与其他方法有没有正交性,$\Delta W, W$之间有什么关系等等,这里只说明了一些我感兴趣的实验,我觉得这是一篇好论文,实验扎实,方法简单,如果你是这个行业的从业者我建议可以自己去阅读一下原文。