先按照顺序列一下这几篇技术首次提交到arxiv的时间,我们按照提交时间来介绍,很多博客都搞不清楚发表时间,甚至把这几种方法张冠李戴,我们还是从原始信息源头进行梳理,这样虽然慢但是可靠。
论文:Adapter: Parameter-Efficient Transfer Learning for NLP 代码:Adapter 时间:2019.2.2
论文:Prefix-Tuning: Optimizing Continuous Prompts for Generation 代码:Prefix-Tuning 时间:2021.01.01
论文:P-tuning: GPT Understands, Too 代码:P-Tuning 时间:2021.03.18
论文:The Power of Scale for Parameter-Efficient Prompt Tuning 代码:Prompt Tuning 时间:2021.4.18
论文:LoRA: Low-Rank Adaptation of Large Language Models 代码:Lora 时间:2021.06.17
论文:BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models 代码:BitFit 时间:2021.06.18
论文:P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks 代码:P-Tuning v2 时间:2021.10.14
论文:T-Few: Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning 代码:T-Few 时间:2022.04.11
Prefix-Tuning
本篇介绍的是Prefix-Tuning,其他的方法在我博客里可以利用LLM这个Tag来检索,按照上面列的时间顺序来读。
这篇关注于两个任务,table-to-text和summarization。补补背景知识,summarization很简单就是把一段话总结成更简单的句子,table-to-text指的是将表格数据转换成自然语言文本的生成任务,例如,给定的表格数据可能包含餐厅名称、菜系、价格、评价等信息,而模型生成的文本可能是一个关于这家餐厅的简单描述,例如"这是一家提供中国菜的咖啡店,价格便宜,顾客评分一般"。
其实这篇方法很简单,假设$x$是模型输入序列,$y$是期望的输出序列。
比如对于table-to-text任务,对表格进行OCR得到的信息为$x$为Harry Potter, Education, Hogwarts。期望整理后输出的text信息$y$为[Sep] Harry Potter is graduated from Hogwarts。
科普一下Transfomer的工作原理,将不同时刻的信息$x_i$输入到Transformer中,会产生对应时刻的激活状态$h_i$,Transfomer有多层,所以$h_i=[h_i^1,h_i^2,…,h_i^n]$,其中$n$代表Transformer的层数,对应$i$时刻的最终输出就是最后一层激活状态的变换,可以表示为$softmax(W_\phi h_i^n)$。
Suffix的含义就是前缀,所以这篇文章就是人为在正常的激活状态前增加几个时刻激活状态,如下图所示,正常的流程是根据$h_3,h_4,h_5,h_6,h_7,h_8$,预测输出$h_9$。现在人为加了$h_1,h_2$这两个激活状态,变成了根据$h_1,h_2,h_3,h_4,h_5,h_6,h_7,h_8$,预测输出$h_9$。注意到$h_1,h_2$是人为构造的,所以如何构造是个难题,那就让网络自己学吧!所以网络微调的目的不是微调网络的参数,而是学习构造的前几个激活状态。

至于添加的前缀激活状态数,是可以选择的,比如上面的例子里是两个,其实可以任意数量。
论文中提到$h_i^n$是由transformer中的key和value组成的,在GPT2中它们各自的维度为1024。若我们把Prefix tuning也视为一个有输入有输出的系统,它的输入信息是添加的前缀token数$v$,输出是会是一个特征,特征长度为$2 \times v \times n \times d$,其中$n$还是transformer层数,$d$为每层激活状态的特征维度,在GPT2中$d$为1024,前面的2代表key和value这两个。可以看PEFT库的Prefix tuning,用法:https://huggingface.co/docs/peft/en/package_reference/prefix_tuning
如果看上面函数的用法,会发现有个属性叫prefix_projection,这是因为作者发现直接让网络去学这个$2 \times v \times n \times d$的特征很难学,甚至还会掉点。所以做法就是先初始化一个人$2 \times v \times n \times d_1$的nn.parameters,然后用两层全连接再变成$2 \times v \times n \times d$大小,在这里$d_1<d$。网络训练好了,直接拿最后的这个$2 \times v \times n \times d$特征就好了,全连接层就可以舍弃了,作者把这个称之为reparametrization,一些博客把他翻译成重参数化,这容易与结构重参数化这个概念相混淆,其实就是这么个简单的做法。
效果
在表格到文字任务中,限制可学习参数量为0.1%时,prefix tuing会超越Adapter和微调最后两层的方法。甚至还能在一些数据集上超越全参数微调,这应该是因为这几个数据集比较小的原因。
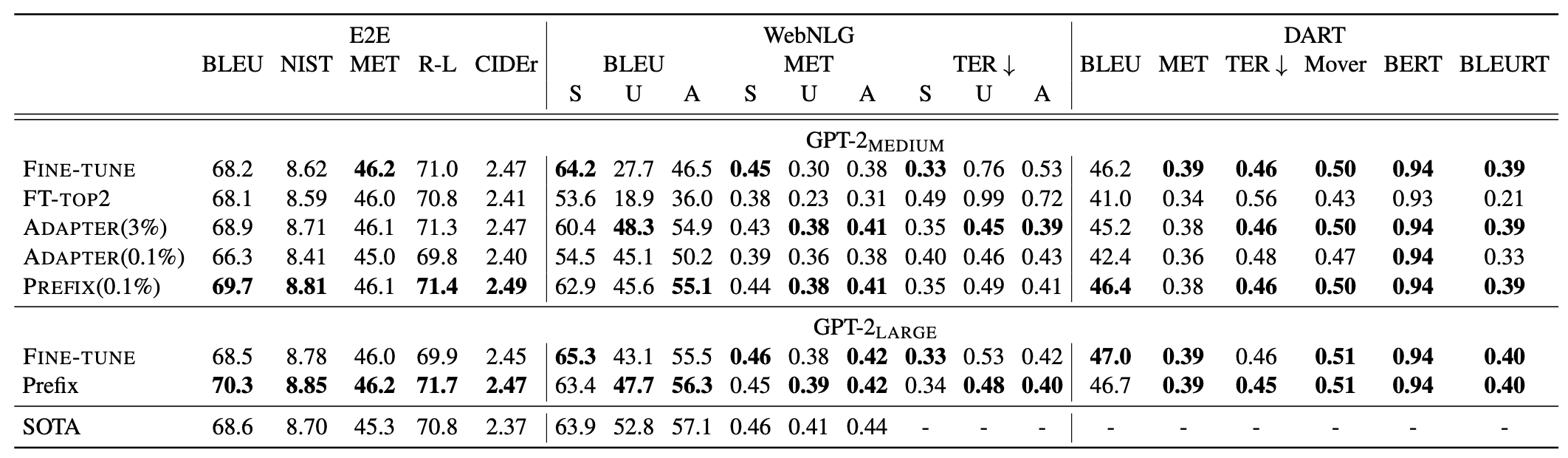
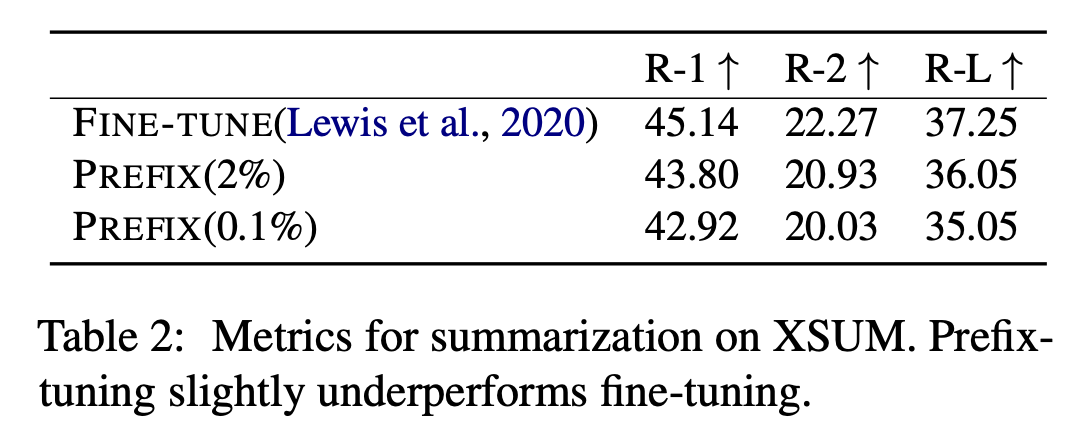
在摘要任务上,因为数据集的样本量上来了,所以就不如全参数微调了。作者分析原因有这几个:(1) XSUM平均包含的示例是表格到文本数据集的4倍;(2) 输入文章的长度是表格到文本数据集平均线性化表格输入的17倍;(3) 摘要可能比表格到文本更复杂,因为它需要阅读理解和从文章中识别关键内容。
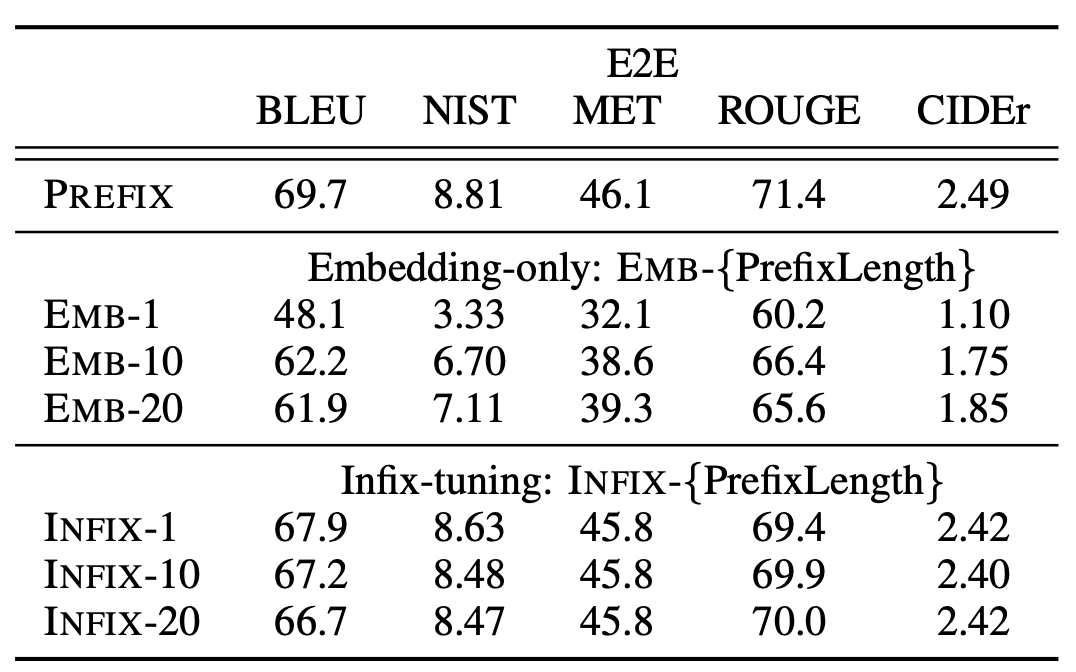
虽然这个方法叫前缀微调,但是放哪个位置都行的,比如在prefix-tuning中,将它们放在序列的开始[PREFIX; x; y]。我们也可以将可训练激活放在x和y之间(即[x; INFIX; y]),并将其称为中缀微调。中缀微调的效果略低于前缀微调。这可能是因为前缀化可以影响x和y的激活,而中缀化只能影响y的激活。
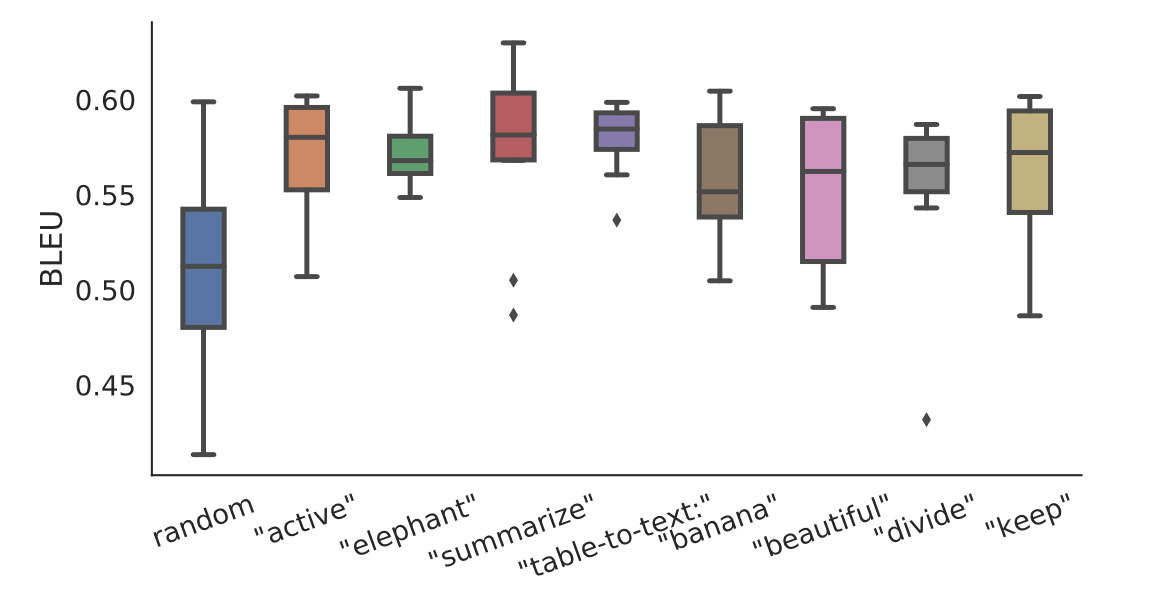
在少量数据微调时,前缀的初始化方式对性能有很大影响。随机初始化会导致性能低且方差大。如下图所示,使用实际单词的激活来初始化前缀可以显著提高生成性能。特别是使用与任务相关的单词(如“summarization”和“table-to-text”)进行初始化比使用与任务无关的单词(如“elephant”和“divide”)进行初始化性能略好,但使用实际单词仍比随机初始化要好。