
先按照顺序列一下这几篇技术首次提交到arxiv的时间,我们按照提交时间来介绍,很多博客都搞不清楚发表时间,甚至把这几种方法张冠李戴,我们还是从原始信息源头进行梳理,这样虽然慢但是可靠。
论文:Adapter: Parameter-Efficient Transfer Learning for NLP 代码:Adapter 时间:2019.2.2
论文:Prefix-Tuning: Optimizing Continuous Prompts for Generation 代码:Prefix-Tuning 时间:2021.01.01
论文:P-tuning: GPT Understands, Too 代码:P-Tuning 时间:2021.03.18
论文:The Power of Scale for Parameter-Efficient Prompt Tuning 代码:Prompt Tuning 时间:2021.4.18
论文:LoRA: Low-Rank Adaptation of Large Language Models 代码:Lora 时间:2021.06.17
论文:BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models 代码:BitFit 时间:2021.06.18
论文:P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks 代码:P-Tuning v2 时间:2021.10.14
论文:T-Few: Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning 代码:T-Few 时间:2022.04.11
Adapter
这篇是这个系列里最早的大模型微调方法,19年就出来了,19年还没有chatgpt,关注这个方向的人应该也没有现在这么多。这个时候先预训练,再到子任务上微调已经成为业内的范式,但全参数微调在每个新任务上都需要训练一个全新的模型,因为模型越来越大,在面对大量下游任务时效率很低。
这篇方法极其简单,感觉一段话就能说明白了,也是辛苦作者憋出来8页,不过这个也不怪作者,不管是期刊还是会议都是有页数限制的。

如上图所示,Adapter方法就是往transformer层中添加Adapter层,右边是Adapter层的结构。
可以看到Adapter层是加在两个前馈层后面的,所以Adapter方法需要微调的参数就是新增的Adapter层,微调参数量会随着transformer的层数线性增长。
Adapter层是一个瓶颈结构,先把原始的$d$维特征投影到一个更小的维度$m$,之后应用非线性函数,最后再次投影回$d$维。包括偏置在内,每层添加的总参数数量是$2md+d+m$。通过设置$m ≪ d$,来保证每个Adapter层的参数量不会很大。
注意到Adapter层也是一个残差结构,所以只要把主路径上的全连接层参数初始化为0,Adapter在一开始的时候就相当于一个全等变换,这样相当于啥也没加,网络应该可以train得起来。
实验
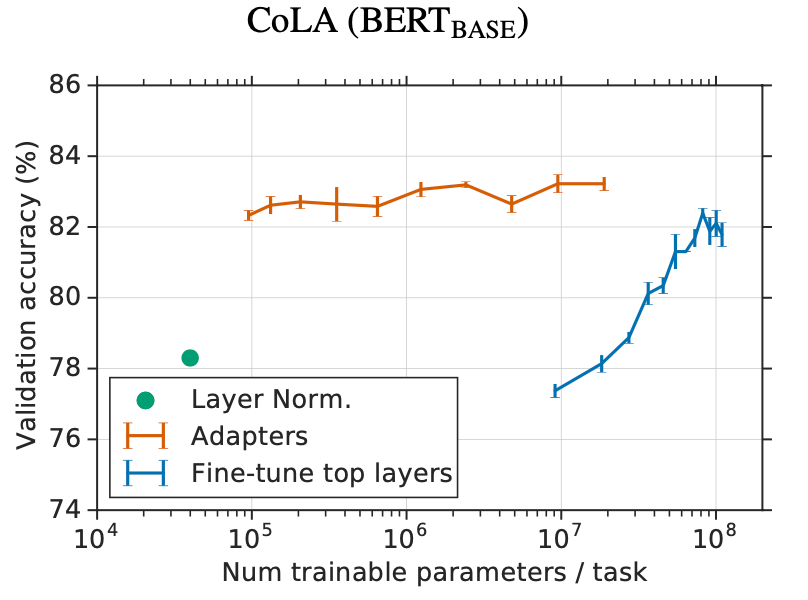
首先作者对比了Adapter和微调最后几层transformer的效果,发现Adapter在相同参数量的情况下基本能够超过后者,在参数量小两个数据级的时候也能达到接近的效果,这说明Adapter在少参数微调的时候还是比较有性价比的。

作者还与仅仅微调transformer中的layer normlization层进行了对比,发现后者效果也是比较差的。
还有一个有点意思的实验,那就是把训练好的Adapter层拿掉一些,之前提到每层transfomer都会对应两个Adatpter层,现在把一些transformer层中的Adatapter删除掉,直接测试看看对最终效果的影响。
解读一下下图,比如说我的transfomer有11层,现在我决定丢弃掉第i层到第j层的Adapter,显然图中的对角线就是丢弃某一层Adapter的效果,可以得到的结论是丢掉哪个单独层对最后的影响都不大,但是如果丢弃的层太多了则会显著影响效果;还能得到的结论是,如果丢弃同样数量的层,丢弃高层会比丢弃低层产生更显著的影响。

最后作者也提到它们也做了一些实验,比如在Adapter层中加归一化层,增加Adapter的层数,实验不同的激活函数,以及用并行的方式把Adatapter插入到主路中去都对性能提升没有用。有意思的是用并行的方式把Adatapter插入到主路中这种方法不就是后来的Lora吗?之所以没用只能说是实验没调好?看来做研究也不能太相信前人的结论,后面我们读到Lora,再来看看为什么Lora会有效。