GRU(Gated Recurrent Unit)是一种用于深度学习中的循环神经网络(RNN)的门控机制。它由Cho等人在2014年提出,旨在解决标准循环神经网络训练过程中的梯度消失问题,比1997年的LSTM晚。GRU通过引入更新门(update gate)和重置门(reset gate)来控制信息的流动,这样可以更好地捕捉到数据中的长期依赖关系。 相比LSTM,使用GRU能够达到相当的效果,并且相比之下更容易进行训练,能够很大程度上提高训练效率,因此很多时候会更倾向于使用GRU。
基本原理
更新门(Update Gate):决定了前一时刻的状态有多少信息需要保留到当前时刻。 重置门(Reset Gate):决定了如何结合新的输入信息和前一时刻的状态信息,以便更新当前状态。
假设我们有一个序列输入 $ x_1, x_2, …, x_t $,GRU单元会对每个时间步$t$ 更新其隐藏状态 $h_t $。以下是GRU的数学表达:
更新门:
$$ z_t = \sigma(W_z \cdot [h_{t-1}, x_t]) $$ 重置门:
$$ r_t = \sigma(W_r \cdot [h_{t-1}, x_t]) $$
候选隐藏状态:
$$ \tilde{h}t = \tanh(W \cdot [r_t * h{t-1}, x_t]) $$(这公式被解析丢了,看下图吧)
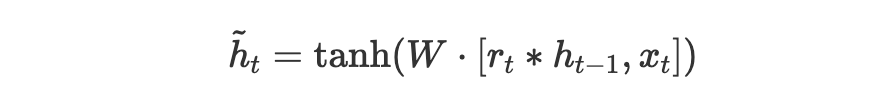
最终隐藏状态:
$$ h_t = (1 - z_t) * h_{t-1} + z_t * \tilde{h}_t $$ 其中,$W_z,W_r$ 和 $W$ 是权重矩阵,$ \sigma $是sigmoid激活函数,$ \tanh$ 是双曲正切激活函数,$*$ 表示逐元素乘法。
下面是一个简化的Python代码示例,展示了如何从头开始实现一个GRU单元。请注意,这个例子是为了教学目的而简化的,并没有包括诸如偏置项、层正规化、dropout等实际应用中常见的细节。
代码
|
|
辅助记忆
想象一下,有一个古老的图书馆,里面存放着无数的书籍,这些书籍记录了一个古老王国的历史。图书馆的管理员是一个智慧的守护者,他的名字叫做Gru。Gru的任务是保护这些知识,并在需要时提供给访问者。但是,图书馆的空间有限,Gru不能同时记住所有的书籍内容,所以他必须决定哪些信息是重要的,值得记住,哪些可以暂时忘记。
更新门(Update Gate): Gru有一个特殊的钥匙串,上面挂着许多小钥匙,这些钥匙代表更新门。每当有新的故事(输入)来到图书馆时,Gru会用这些钥匙来决定应该打开哪些书的锁,也就是决定保留哪些旧的故事。如果一个钥匙转动得越多,那本书的内容就被保留得越完整。这样,Gru就可以平衡新旧信息,确保图书馆的知识是最新的,同时也不会丢失重要的历史。
重置门(Reset Gate): Gru还有一块神奇的橡皮,这块橡皮代表重置门。当一个新的故事与图书馆中的某些旧故事冲突时,Gru会用这块橡皮擦掉旧故事的一部分,以便更好地融合新的信息。这就像是他在重新评估旧知识的重要性,决定是否需要重写历史的某些章节。
候选隐藏状态和最终隐藏状态: 每次Gru使用钥匙和橡皮时,他都会在心中构建一个新的故事草稿,这就是候选隐藏状态。然后,他会用更新门上的钥匙来决定,应该保留多少旧的故事,以及应该加入多少新的草稿内容。这个最终的故事就是最终隐藏状态,它是旧知识和新知识的结合,由Gru精心维护和更新。
随着时间的推移,Gru变得越来越熟练,他的图书馆也越来越丰富。每个新来的访问者都能从中获得最相关和最准确的知识,因为Gru总是能够找到完美的平衡,保留重要的历史,同时接受新的故事。